
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- OpenCV
- nestJS
- 카카오 코테
- spring boot
- @Component
- 카카오 알고리즘
- 스프링
- thymeleaf
- 해시
- Spring
- python
- nestjs auth
- AWS
- C++
- 시스템호출
- 프로그래머스
- 파이썬
- git
- 가상면접사례로배우는대규모시스템설계기초
- 컴포넌트스캔
- Nodejs
- 카카오
- 코딩테스트
- 코테
- 구조체배열
- 알고리즘
- TypeORM
- @Autowired
- nestjs typeorm
- C언어
- Today
- Total
공부 기록장 💻
[NLP기초] 모델 학습의 파이프라인 본문
"Do It! BERT와 GPT로 배우는 자연어처리" 1장 정리
학습 목표
모델 학습의 전체 파이프라인에 대해 알아보자. 해당 학습 파이프라인은 자연어 처리 모델이 수행하는 문서 분류, 개체명 인식, 질의응답, 문서 검색, 문장 생성의 5가지 과제에 상관없이 공통적으로 적용된다.
학습 파이프라인을 그림으로 나타내면 다음과 같다.

모든 실습은 ratsnlp 라는 오픈소스 파이썬 패키지를 사용하고, 패키지는 구글 Colab 환경에서 실습을 진행하게 된다.
1. 각종 설정값 정하기
모델을 만들기 위해선 가장 먼저 각종 설정값을 결정해야 한다.
- 어떤 pre-train model을 사용할 것인가?
- 학습에 사용할 데이터는 무엇인가?
- 학습 결과는 어디에 저장할 것인가?
하이퍼파라미터(hyperparmeter)란 모델 구조와 학습 등에 직접 관계덴 설정값으로, learning rate, batch size
pre-train model, downstream corpus, learning rate, batch_size를 비롯한 각종 설정값을 정하는 코드 예시는 다음과 같다.
from ratsnlp.nlpbook.classification import ClassificationTrainArguments
args = ClassificationTrainArguments(
pretrained_model_name="beomi/kcbert-base",
downstream_corpus_name="nsmc",
downstream_corpus_root_dir="/content/Korpora",
downstream_model_dir="/gdrive/My Drive/nlpbook/checkpoint-doccls",
learning_rate=5e-5,
batch_size=32,
)
2. 데이터 내려받기
pre-train 을 마친 모델은 downstream 데이터로 파인튜닝하는 실습을 진행하게 된다. fine-tuning을 하려면 downstream 데이터를 미리 내려 받아 둬야 한다. 영화 리뷰 말뭉치인 NSMC(Naver Sentiment Movie Corpus)가 대표적인 예이다.
아래 코드는 downstream_corpus_name 에 해당하는 말뭉치를 내려 받아 downstream_corpus_root_dir 아래에 저장한다. 위에서 설정한 args에 따라 nsmc를 코랩 환경 로컬의 content/Korpora 디렉터리에 저장하는 것이다.
from Korpora import Korpora
Korpora.fetch(
corpus_name=args.downstream_corpus_name,
root_dir=args.downstream_corpus_root_dir,
force_download=True,
)
위에서 import한 패키지는 다양한 한국어 말뭉치를 쉽게 내려받고 전처리 할 수 있도록 도와주는 Korpora 오픈소스 파이썬 패키지이다. (https://github.com/ko-nlp/Korpora)
Github 를 자세히 살펴보니, 곳곳에 산재해 있는 데이터의 각기 다른 파일 포맷과 저장 형식을 다루어야 하는 불편함을 덜기 위해, 말뭉치 라는 뜻의 영어 단어 corpus 의 복수형인 corpora 에서 착안해 이름이 지어진 Korpora (Korean Corpora의 준말) 을 통해 한국어 자연어 차리를 다루도록 돕는 패키지라는 것을 이해할 수 있었다.
3. 프리트레인을 마친 모델 준비하기
대규모 말뭉치를 활용한 pre-train에는 많은 리소스가 필요한데, 미국 자연어 처리 기업 huggingface 에서 만든 트랜스포머(transformers) 라는 오픈소스 파이썬 패키지를 통해, 단 몇 줄만으로도 모델을 사용할 수 있도록 도와준다.
아래는 hugging face model hub에 등록한 kcbert-model을 준비하는 코드 예시이다. 위에서 args 설정값의 args.pretrained_mode_name 에 beomki/kcbert-base 라고 선언해 두었으므로, 코드를 실행하면 kcbert-base 모델을 사용할 수 있는 상태가 되는 것이다.
from transformers import BertConfig, BertForSequenceClassification
pretrained_mode_config = BertConfig.from_pretrained(
args.pretrained_mode_name,
num_labels=2,
)
model = BertForSequenceClassification.from_pretrained(
args.pretrained_model_name,
config=pretraiend_model_config,
)
4. 토크나이저 준비하기
자연어 처리 모델의 입력은 대게 토큰(token)으로, 토큰은 문장보다 작은 단위이다. 한 문장은 여러 토큰으로 구성되며, 토큰 분리 기준은 띄어쓰기, 또는 의미의 최소 단위인 형태소(morpheme) 등으로 때에 따라 다룰 수 있다.
문장을 토큰 시퀀스(token sequence) 로 분석하는 과정을 토큰화(tokenization) 라 하며, 토큰화를 수행하는 프로그램을 토크나이저(tokenizer)이라 한다. 이 책에서는 BPE(Byte Pair Encoding) 이나 워드피스(wordpiece) 알고리즘을 채택한 토크나이저를 실습에 활용한다.
래는 kcbert-base 모델이 사용하는 토크나이저를 준비하는 코드 예시이다.
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
args.pretrained_model_name,
do_lower_case=False,
)
5. 데이터 로더 준비하기
PyTorch 는 딥러닝 모델의 학습을 지원하는 파이썬 라이브러리로, 파이토치는 Data Loader을 포함하고 있다.
Data Loader는 데이터를 batch 단위로 모델에 밀어 넣어주는 역할을 하며, 전체 데이터 가운데 일부 인스턴스를 뽑아 배치를 구성한다. Dataset 은 데이터 로더의 구성 요소 가운데 하나로, 여러 인스턴스(문서+레이블)을 보유하고 있다.
데이터 로더가 배치를 만들 때 인스턴스를 뽑는 방식은 pytorch 사용자가 자유롭게 정할 수 있다. 아래의 경우 크기가 3인 배치를 구성하는 예시로, 배치 1의 경우 0,3,6번 인스턴스, 배치 2의 경우 1,4,7번 인스턴스로 구성한 경우이다.

배치는 그 모양이 고정적이어야 할 때가 많다. 즉, 배치에 있는 문장들의 토큰(input_ids) 개수가 같아야 한다. 예를 들어 데이터셋의 0, 3, 6번 인스턴스로 구성된 배치에 대하여, 각 인스턴스의 토큰 개수가 5,3,4개라고 가정해보자. 제일 긴 길이로 맞춘다면 0번 인스턴스의 길이인 5에 따라 3, 6번 인스턴스의 길이를 늘려야 하는 것이다.
다음 그림에 나타난 것처럼, 인스턴스 3, 6번의 input_ids 토큰 길이가 각각 3, 4 에서 0을 덧붙여 길이가 5가 된 것을 확인할 수 있다.

이처럼 배치의 모양 등을 정비해 모델의 최종 입력으로 만들어 주는 과정을 컬레이트(collate) 라고 한다. 컬레이트 과정에서는 파이썬 리스트(list)에서 파이토치 텐서(tensor) 로의 변환 등 자료형 변환도 포함된다. 컬레이트 수행 방식 역시 pytorch 사용자가 자유롭게 구성할 수 있다.
아래는 문서 분류를 위한 데이터 로더를 준비하는 예시이다.
from torch.utils.data import DataLoader, RandomSampler
from ratsnlp.nlpbook.classification import NsmcCorpus, ClassficiationDataset
corpus = NsmcCorpus()
train_dataset = ClassificationDataset(
args=args,
corpus=corpus,
tokenizer=tokenizer,
mode="train",
)
train_dataloader = DataLoader(
train_dataset,
batch_size=args.batch_size,
sampler=RandomSampler(train_dataset, replacement=False),
collate_fn=nlpbook.data_collater,
drop_last=False,
num_workers=args.cpu_workers,
)
자연어 처리 모델의 입력은 토큰 시퀀스로 분석된 자연어인데, 각 토큰은 그에 해당하는 정수로 변환된 형태라고 할 수 있다. 이러한 변환 과정을 인덱싱(indexing) 이라 하며 토큰화 과정에서 함께 수행하게 된다.
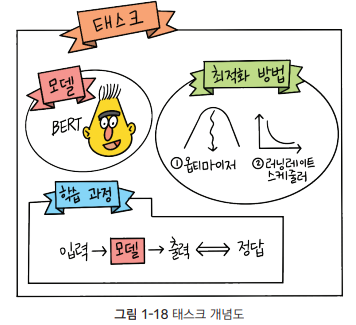
6. 태스크 정의하기
모델 학습을 할 때 이 책에선 pytorch lightning 이라는 라이브러리를 사용하는데, 이는 딥러닝 모델을 학습할 때 반복적인 내용을 수행해줘 사용자가 모델 구축에만 신경쓸 수 있도록 돕는 라이브러리이다.
pytorch lightning이 제공하는 lightning 모듈을 상속받아 task를 정의할 수 있다. 이 task는 앞서 준비해온 모델과 최적화 방법, 학습 과정 등이 정의되어 있다. 최적화(optimization)이란 특정 조건에서 어떤 값이 최대 또는 최소가 되도록 하는 과정을 가리킨다. 우리는 모델의 출력과 정답 사이의 차이를 작게 만드는 데 관심이 있는데, 이를 위해 optimzer, learning rate scheduler 등을 정의할 수 있다.
모델 학습은 배치 단위로 이루어진다. 배치를 모델에 입력한 뒤, 모델 출력을 정답과 비교해 차이를 계산한다. 이후 그 차이를 최소화하는 방향으로 모델을 업데이트 하는데, 이러한 일련의 순한 과정을 step 이라 한다. task의 학습 과정에는 1회 step 에서 벌어지는 일들을 정의해 둔다.
7. 모델 학습하기
trainer는 pytorch lightning에서 제공하는 객체로, 실제 학습을 수행하게 된다. 이 트레이너는 GPU 등의 하드웨어 설정, 학습 기록 로깅, 체크포인트 저장 등 복잡한 설정들을 알아서 처리해준다.
아래 코드는 문서 분류 모델을 학습하는 예시로, task와 trainer을 정의한 다음 앞서 준비한 data loaer을 가지고 fit() 함수를 호출하여 학습을 시작한다.
from ratsnlp.nlpbook.classification import ClassificationTask
task = ClassificationTask(model, args)
trainer = nlpbook.get_trainer(args)
trainer.fit(
task,
train_dataloader=train_dataloader,
)
'# Tech Studies > NLP' 카테고리의 다른 글
| [NLP기초] 트랜스퍼 러닝이란? Transfer Learning (0) | 2022.12.28 |
|---|---|
| [NLP기초] 딥러닝 기반 자연어 처리 모델이란? (0) | 2022.12.28 |

