
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Nodejs
- @Component
- 알고리즘
- nestJS
- Spring
- 가상면접사례로배우는대규모시스템설계기초
- nestjs typeorm
- TypeORM
- 해시
- @Autowired
- thymeleaf
- 카카오 코테
- 코딩테스트
- 카카오
- 코테
- OpenCV
- 프로그래머스
- 컴포넌트스캔
- spring boot
- python
- 구조체배열
- C언어
- nestjs auth
- git
- 카카오 알고리즘
- 파이썬
- AWS
- 스프링
- 시스템호출
- C++
- Today
- Total
공부 기록장 💻
[NLP기초] 딥러닝 기반 자연어 처리 모델이란? 본문
"Do It! BERT와 GPT로 배우는 자연어처리" 1장 정리
학습 목표
딥러닝 기반에 둔 자연어 처리 모델의 개념과 학습 방법을 살펴 보자.
기계의 자연어 처리
모델(model)이란 입력을 받아 어떤 처리를 수행하는 함수(function)라 할 수 있다.
아래 그림과 같이 모델의 출력은 어떤 사건이 일어날 가능성을 의미하는, 0과 1 사이의 값의 확률(probability)이라는 점에 주목해야 한다. 즉, 모델이란 어떤 입력을 받아 해당 입력이 특정 범주일 확률을 반환하는 확률 함수이다.

그렇다면, 자연어 처리 모델의 입력은 자연어, 즉 사람의 말이다. 이를 정리해보면 자연어 처리 모델은 자연어를 입력 받아 해당 입력이 특정 범주일 확률을 반환하는 확률 함수라고 할 수 있다.
예를 들어 영화 리뷰의 감성(sentiment)을 맞히는 자연어 처리 모델을 만든다고 가정하였을 때, 감성 분석 모델을 아래 수식처럼 함수 f로 쓸 수 있다. 이 모델은 자연어(문장)을 입력 받아 계산 과정을 거쳐 해당 문정이 긍정일 확률, 중립일 확률, 그리고 부정일 확률을 출력한다.

그렇다면 어떤 모델을 선택해야 하는가?
모델 종류는 다양하기 때문에, 입력(자연어)의 특성과 목적(감성 분석) 등에 따라 최적이라고 판단되는 것을 선택하면 된다.
딥러닝(deep learning)은 가장 각광받고 있는 모델의 종류인데, 이는 데이터 패턴을 스스로 익히는 인공지능의 한 갈래이다. 여기서 depp이란, 많은 은닉층(hidden layer)을 사용한다는 의미로, 딥러닝은 이미지 분류, 음성 인식 및 합성, 자연어 처리 등 다양한 분야에서 널리 쓰이고 있다.
딥러닝 가운데에서도 BERT(Bidirectional Encoder Representations from Transformers)나 GPT(Generative Pre-trained Transformer) 등이 특히 주목박고 있는 모델이다. 이들을 딥러닝 기반 자연어 처리 모델이라고 한다.

딥러닝 기반 자연어 처리 모델의 출력 역시 확률이다. 그러나 사람은 자연어 형태의 출력을 선호하기 때문에, 출력된 확률을 후처리(post processing)하여 자연어 형태로 다음과 같이 바꾸어 활용할 수 있다.

이처럼 자연어 처리 모델의 개요를 요약해보자면 다음과 같다.
1. 자연어를 입력 받는다.
2. 해당 입력이 특정 범주일 확률을 출력하고,
3. 이 확률값을 적당히 후처리하여 자연어 형태로 가공하여 반환한다.
딥러닝 모델의 학습
딥러닝 자연어 처리 모델을 만들기 위해서는 우선 학습 데이터(training data)가 필요하다.
다음과 같이 각 문장에 '감성'이라는 레이블(label)을 달아 놓은 자료, 데이터가 필요한 것이다.

다음으로는 학습(train)의 과정을 거치게 된다. 이 과정을 통해 모델이 데이터의 패턴(pattern)을 스스로 익히게 된다.
예를 들어 "단언컨대 이 영화 재미 있어요" 라는 문장을 학습한다고 가정하였을 때, 학습 초기에 확률 함수 f는 이 문장을 입력 받았을 때 다음과 같이 출력할 것이다. 문장이 어떤 감성을 지니고 있는지 전혀 모르는 상태이다.

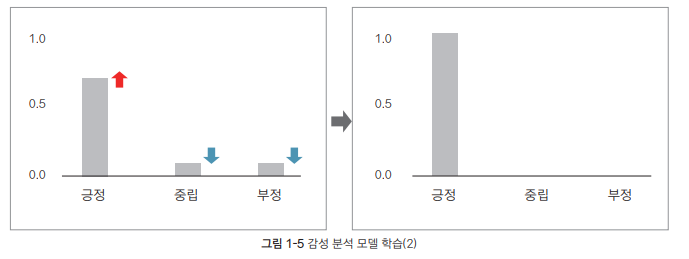
이 문장의 감성(정답)이 [1 0 0] 임을 우리는 알고 있지만, 해당 모델의 출력을 정답과 비교해보았을 때 상대적으로 중립/부정일 확률은 높고 긍정 확률이 낮다. 따라서 f가 이 문장을 입력 받을 때에 긍정 점수는 높이고, 중립/부정 점수는 낮추도록 모델을 다음과 같이 업데이트 해야 한다.

업데이트를 했는데도 모델의 출력이 여전히 정답과 차이가 있다면 한 번 더 조정해 준다. 이러한 업데이트를 반복하면 결국 f가 정답에 가까운 출력을 내게 된다. 이렇게 모델을 업데이트하는 과정 전체를 학습(train)이라 한다. 모델이 입력과 출력 사이의 패턴을 스스로 익히는 과정, 출력이 정답에 가까워지도록 모델을 업데이트하는 과정이라 볼 수 있다.
'# Tech Studies > NLP' 카테고리의 다른 글
| [NLP기초] 모델 학습의 파이프라인 (0) | 2022.12.28 |
|---|---|
| [NLP기초] 트랜스퍼 러닝이란? Transfer Learning (0) | 2022.12.28 |

