
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- C언어
- 프로그래머스
- OpenCV
- 시스템호출
- nestjs auth
- 코테
- 가상면접사례로배우는대규모시스템설계기초
- thymeleaf
- nestJS
- 파이썬
- 컴포넌트스캔
- 알고리즘
- C++
- 카카오 코테
- 카카오 알고리즘
- @Component
- TypeORM
- python
- 구조체배열
- spring boot
- Spring
- nestjs typeorm
- 코딩테스트
- 스프링
- git
- AWS
- 해시
- @Autowired
- Nodejs
- 카카오
- Today
- Total
공부 기록장 💻
[Python/Data Analysis] Fitbit 기초 운동량 데이터를 분석해보자 본문
Fitbit 프로젝트 개요
본 프로젝트는 2022년 2학기 ‘빅데이터 프로그래밍’ 과목에서 수행하는 최종 기말 프로젝트로, Fitbit 활동량 데이터를 기반으로 하여 데이터를 분석하는 과제를 수행하는 것이 목표이다. 프로젝트에 활용하기 위해 수업 시간에 주어진 원본 데이터는 result_calories.txt, results_distance.txt, results_steps.txt 의 총 세 텍스트 파일에 저장되어 있는 calories, distance, steps 데이터이다. 각 데이터는 아래 사진과 같이, 2021년 4월 7일부터 2021년 11월 14일까지의 Date 객체와 각 데이터의 값이 저장되어 있다.
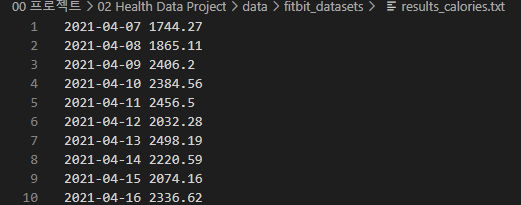
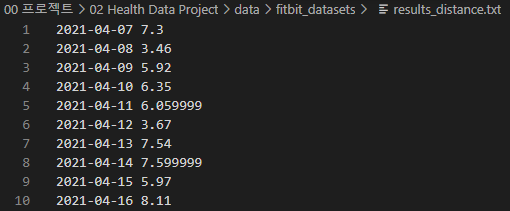
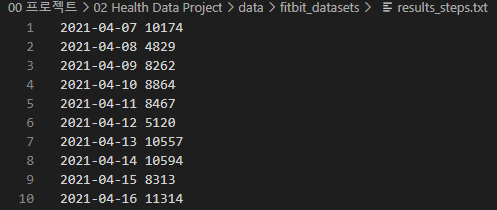
위의 데이터를 활용하고자 했으나, 수업 시간에 명시된 것처럼 순천향대학교 AI&빅데이터 센터의 AI 플랫폼에서 제공하고 있는 데이터의 범위와 개수가 훨씬 넓고 활용도가 높다고 판단하여, 해당 플랫폼에서 원본 Fitbit 데이터를 export 하여 활용하는 것으로 변경하였다.
Fitbit 데이터 출처
따라서 데이터는 AI 플랫폼의 Fitbit 부문(http://aibig.sch.ac.kr/data/listPageDATAFitbit.do)에서 fitbit activity sample data 중, 비교적 최근에 수집되었으며 충분히 많은 양의 데이터를 보유하고 있는, 23BZR의 고유 번호를 갖는 데이터를 다운 받았다. 해당 fitbit 데이터는 2022년 10월 5일부터 2022년 11월 22일까지, 약 7주 간의 활동량을 기록한 데이터이다.
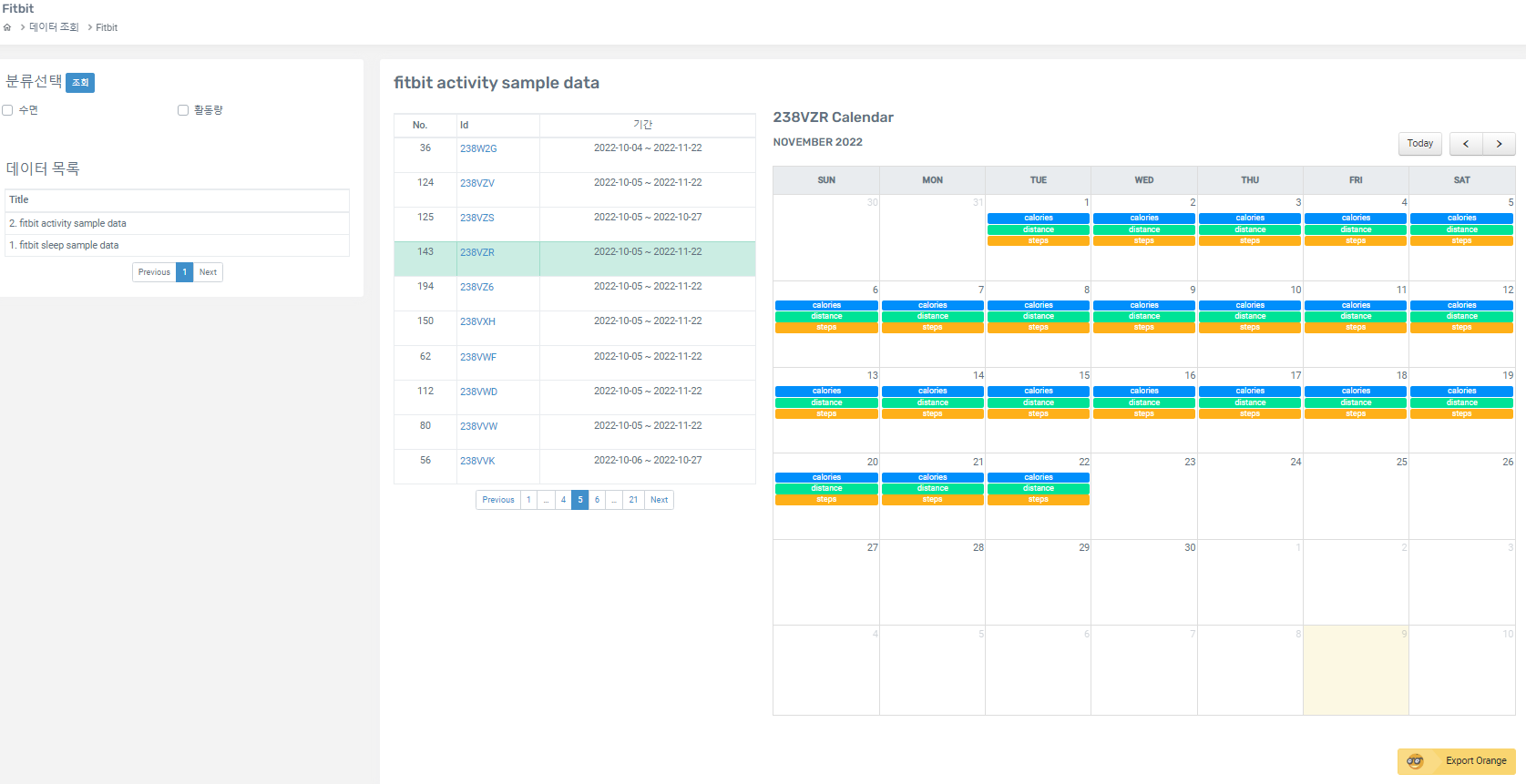
위 데이터를 Export 한 후, csv 파일을 열어보면 다음과 같이 나타난다.
A, B 두 열에 처음 세 행에는 자료형에 대한 헤더가, 그리고 4번째 행부터 A열에는 수집한 데이터의 id 값이, B열에는 데이터가 json 형식의 문자열로 저장되어 있다.
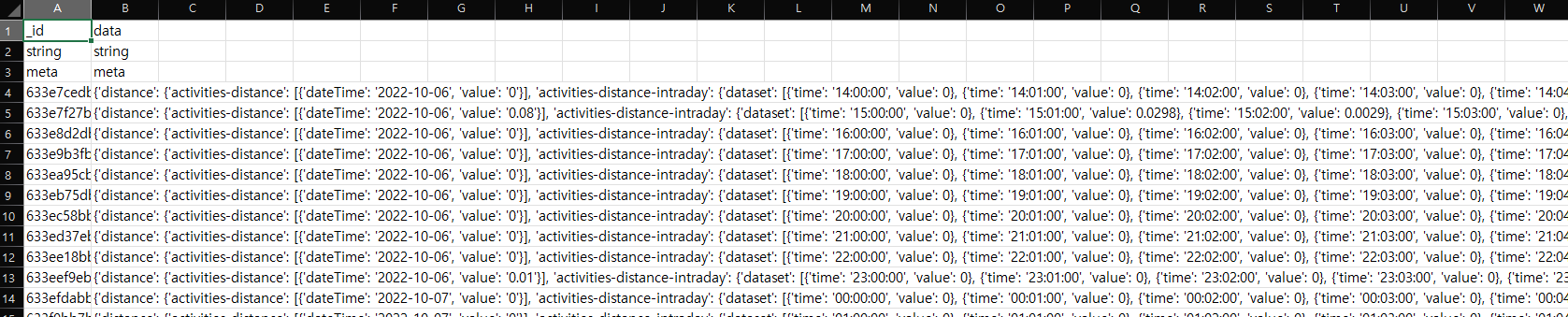
해당 json 데이터가 어떠한 값을 갖고 있는지 알아보자.
데이터 전체는 약 7주간 수집된 연속적인 시계열 데이터인데,
각 로우는 총 1시간동안 측정된 활동량 데이터를 포함하고 있는데, 각 value 의 구간은 1분 단위이다.
json 데이터를 정리해보면, 다음과 같다. 데이터의 길이가 너무 길어지므로, 한 예시로 2022년 11월 22일, 오전 4시경 측정된 데이터의 일부만 가져와 정리해보았다.
크게 distance, calories, steps 가 있는데 distance를 예로 자세히 살펴보자.
activites-distance는 배열 하나를 포함하는데, 데이터가 측정된 날짜와 value 값을 갖고 있다.
activites-distance-intraday의 dataset에는 1분 단위로 측정된 데이터 값들이 총 60개가 포함되어 있다.
각 데이터는 time과 value 값을 갖는다.
datasetInterval은 1, datasetType은 minute으로, 1분 단위로 측정되었다는 것을 알려준다.
나머지 calories, steps도 distance와 동일한 형식으로 표현되어 있는데,
다만 calories의 경우 value 뿐 아니라 level, mets(METs - metabolit equivalent) 데이터가 추가되어 있음을 확인할 수 있다.
{'distance': {
'activities-distance': [{'dateTime': '2022-11-22', 'value': '0'}],
'activities-distance-intraday': {
'dataset':[
{'time': '04:00:00', 'value': 0},
{'time': '04:01:00', 'value': 0},
{'time': '04:02:00', 'value': 0},
{'time': '04:03:00', 'value': 0},
{'time': '04:04:00', 'value': 0}
],
'datasetInterval': 1,
'datasetType': 'minute'
}
},
'calories': {
'activities-calories': [{'dateTime': '2022-11-22', 'value': '72.55'}],
'activities-calories-intraday': {
'dataset': [
{'level': 0, 'mets': 10, 'time': '04:00:00', 'value': 1.2091},
{'level': 0, 'mets': 10, 'time': '04:01:00', 'value': 1.2091},
{'level': 0, 'mets': 10, 'time': '04:02:00', 'value': 1.2091},
{'level': 0, 'mets': 10, 'time': '04:03:00', 'value': 1.2091}
],
'datasetInterval': 1,
'datasetType': 'minute'
}
},
'steps': {
'activities-steps': [{'dateTime': '2022-11-22', 'value': '0'}],
'activities-steps-intraday': {
'dataset': [
{'time': '04:00:00', 'value': 0},
{'time': '04:01:00', 'value': 0},
{'time': '04:02:00', 'value': 0},
{'time': '04:03:00', 'value': 0},
],
'datasetInterval': 1,
'datasetType': 'minute'
}
}
}
우선 import 한 모듈과 라이브러리들은 다음과 같다.
데이터 분석의 기초가 되는 자료형 DataFrame 객체로 데이터를 다룰 수 있도록 하는 pandas 라이브러리,
csv 파일 내 json 문자열 객체를 다루도록 하는 json 모듈,
시계열 데이터를 다루도록 날짜-시간 자료형을 다룰 수 있도록 하는 datetime 라이브러리,
그래프 시각화를 위한 matplotlib와 seaborn 라이브러리를 import 해주었다.
import pandas as pd
import json
from datetime import datetime
import matplotlib.pyplot as plt
import seaborn as sns
main 함수에서 작성한 함수들을 호출하여 데이터를 분석할 것이다.
main 함수에서 origin_data() 함수를 호출하고 다시 작은 단위의 기능들을 각각 수행하는 여러 함수들을 호출하는 방식이다.
filepath에는 우선 로컬에 저장되어 있는 파일의 경로를 지정하였다.
데이터 분석의 순서는 다음과 같다.
1. get_data() 함수를 통해 데이터를 로드하고, json 문자열을 python 객체로 변환한다.
2. summarize() 함수를 통해 기본적인 데이터의 정보와 통계를 분석한다.
3. get_daily_result(), visualize_daily_data() 함수를 통해 하루 단위로 묶은 데이터들의 분포와 값을 확인한다.
4. result_by_time_series()를 통해 일부 날짜 구간에서 추출한 데이터를 분석하고 시각화한다.
5. visualize()와 pariplot()를 통해 전체 데이터를 시각화 하고 칼럼 간의 상관 관계를 확인한다.
def origin_data():
filepath = '00 프로젝트/02 Health Data Project/data/fitbit_datasets/1005-1122.csv'
data = get_data(filepath)
summarize(data)
get_daily_result(data)
visualize_daily_data(data)
result_by_time_series(data)
visualize(data)
pairplot(data)
def main():
origin_data()
if __name__ == '__main__': # main()
main()
이제 본격적으로 각각의 순서에 맞게 데이터를 분석해보도록 하자.
Fitbit 데이터 로드
먼저, csv 파일로부터 데이터를 읽어서 pandas의 Dataframe 객체로 저장해보자.
우선 위에서 확인한 바와 같이, 저장하고자 하는 데이터 칼럼은 크게 distance, level, mets, calories, steps 가 있을 것이다.
1. 추가적으로 dates, time 도 칼럼으로 포함되면 시계열 데이터를 처리하고 분석하는데 있어 도움이 되리라 생각하여, 빈 Dataframe 객체를 만들 때 dates 컬럼을 추가하였다.
2. pandas의 read_csv() 메서드를 이용해 파일을 읽어 객체를 우선 df에 저장하고, 수집된 각 데이터에 대한 고유한 id 값은 필요 없으므로, data 열에 해당하는 로우들만 data에 저장하도록 한다.
3. 첫 두 행에는 자료, meta 데이터에 대한 값이 들어있으므로 2번 행부터 데이터를 정제해보도록 한다. 전체 데이터 중, 두 로우에 대해서 distance 데이터에 대해 'Error'라는 문자열이 발견되었기 때문에, 이는 전체 문자열 중 'Error'를 포함하고 있는지 여부를 판단하여 처리하였다.

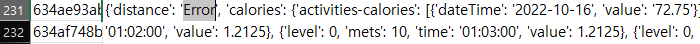
4. 각 데이터를 감싸고 있는 ' 를 " 로 변경한다. json 문자열은 기본적으로 큰따옴표 " 로 각 데이터를 감싸는데, csv 파일에 저장되어 있는 json 문자열은 작은 따옴표 ' 로 표현이 되어 있었다. json 모듈의 loads() 메서드를 이용해 해당 문자열을 파싱하여 Python 객체로 저장한다.
5. 다음으로는 각각의 데이터를 Dataframe 객체로 저장하고, 전체 fitbit_data로 병합하는 작업이다.
d_date에는 distance의 activities-distance 중 첫번째 행에 들어 있는 dateTime 값을 가져와 해당 날짜 문자열을 저장한다. d_distance, d_caloires, d_steps에는 각 데이터의 dataset을 저장하고, 세 Dataframe 객체를 'time' 칼럼을 기준으로 하여 fitbit으로 병합한다.
fitbit의 칼럼들을 각각 지정하여 재색인하고 'dates' 칼럼에 d_date 값을 넣어 새로운 칼럼을 만든다.
fitbit의 인덱스는 d_date와 time 값을 합하여 pandas의 DateTimeIndex 메서드를 이용하여 날짜-시간 자료형으로 설정한다. (즉, 날짜-시간 자료형을 인덱스로 지정하여, 시계열 Dataframe 객체로 변환하는 것이다.)
마지막으로, 초반에 만든 데이터 프레임 객체 fitbit_data에 concat() 함수를 이용해 각 로우에 대한 데이터들을 추가해 나간다.
def get_data(filename):
fitbit_data = pd.DataFrame([], columns = ['distance', 'level', 'mets', 'calories', 'steps', 'dates'], dtype=float)
df = pd.read_csv(filename)
data = df['data']
for i in range(2, len(data)):
ex_data = data[i]
if 'Error' in ex_data:
continue
ex_data = ex_data.replace("'", '"')
jsonData = json.loads(ex_data)
d_date = jsonData['distance']['activities-distance'][0]['dateTime']
d_distance = pd.DataFrame(jsonData['distance']['activities-distance-intraday']['dataset'])
d_calories = pd.DataFrame(jsonData['calories']['activities-calories-intraday']['dataset'])
d_steps = pd.DataFrame(jsonData['steps']['activities-steps-intraday']['dataset'])
final = pd.merge(d_distance, d_calories, on='time')
fitbit = pd.DataFrame(pd.merge(final, d_steps, on='time'))
fitbit.columns = ['time','distance', 'level', 'mets', 'calories', 'steps']
fitbit['dates'] = d_date
fitbit.index = pd.DatetimeIndex(str(d_date) + ' ' + fitbit['time'])
fitbit_data = pd.concat([fitbit_data, fitbit])
return fitbit_data
데이터 정보 확인
이렇게 정제되어 만들어진 최종 DataFrame 객체를 확인해보도록 하자.
def summarize(data):
print(data.head(200))
print(data.tail(200))
print(data.describe())
print(data.info())
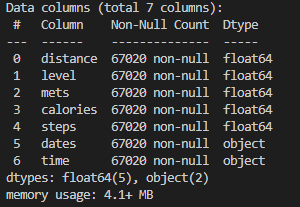
head(), tail() 메서드를 이용해 앞쪽 데이터와 뒤쪽 데이터를 확인해보면 다음과 같다.
인덱스로는 날짜-시간 자료형의 데이터가,
칼럼으로는 distance, level, mets, caloires, steps, dates, time이 나타난 것을 확인할 수 있다.
데이터를 살펴보면, 10월 6일 오후 2시부터 11월 22일 오전 4시 49분의 데이터임을 알 수 있다.
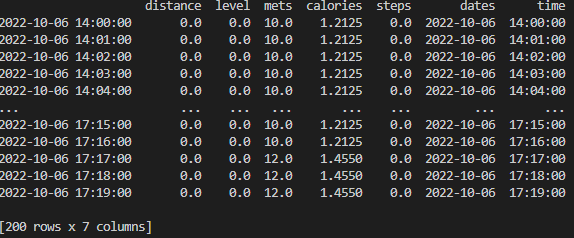
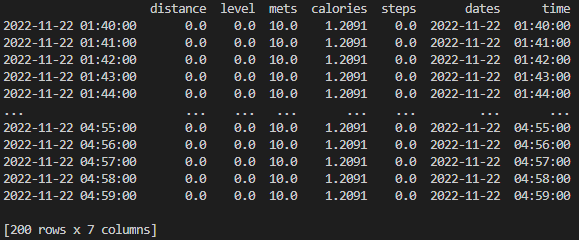
describe()와 info() 메서드를 통해 데이터의 통계를 확인해보자.
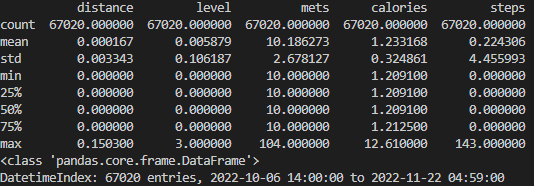
count를 보니, 총 67,020개의 로우가 있음을 알 수 있는데, 하루에 60(1시간)x24(24시간)x7(일주일)x7(약 7주)를 계산해보면 결과가 70,560으로, 67,020의 데이터는 7주가 조금 안 되는 기간 동안 수집된 데이터라는 것을 다시 한 번 확인할 수 수 있다.
distance의 경우 평균값이 0.000167, 최대값이 0.1503으로 매우 작은 값을 띈다는 것을 확인할 수 있다.
level의 경우도 마찬가지로 평균값이 0.005879, 최대값이 3으로 distance에 비해서는 범위는 상당하지만 값 자체의 크기는 매우 작다.
mets의 경우 평균값이 약 10.19이고 최대값이 104이다. 최소값이 10이고, 25%, 50%, 75% 값 모두 10으로, 기본적으로 10이라는 값을 베이스로 하는 것 같다. 다만 최대값이 평균에 비하면 매우 큰 104라는 값을 띄는 것으로 보아 조금 의아했다.
calories의 평균값은 약 1.233이고, min, 25%, 50% 값 모두 약 1.21, 75% 값만 조금 큰 1.2125, 그리고 max 값은 12.61로 확연히 크다.
steps는 평균값이 약 0.224이고 25%, 50%, 75% 값 모두 0인데, max 값이 143으로 매우 크다.
하루 단위 데이터 확인
다음으로, 1분 단위보다 조금 더 큰 단위를 지정하여 데이터의 분포 값을 확인해보자.
하루 단위로 데이터 값들을 확인해보자.
pandas의 groupby 메서드를 이용해 'dates'를 기준으로, 결과를 sum() 합계 메서드를 통해 도출하여 daily_result에 저장하고, main() 함수에서 이 데이터 값을 이용해 그래프로 시각화하도록 아래 두번째 함수를 호출해보자.
* groupby 메서드 참고 : https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html
def get_daily_result(data):
daily_result = pd.DataFrame(data.groupby(['dates']).sum(), columns=['distance', 'level','mets', 'calories', 'steps'])
print(daily_result.head(200))
return daily_result
def visualize_daily_data(data):
data.plot(x_compat=True, rot=90)
plt.suptitle('2022/10/05 ~ 2022/11/12 Fitbit Data')
plt.show()
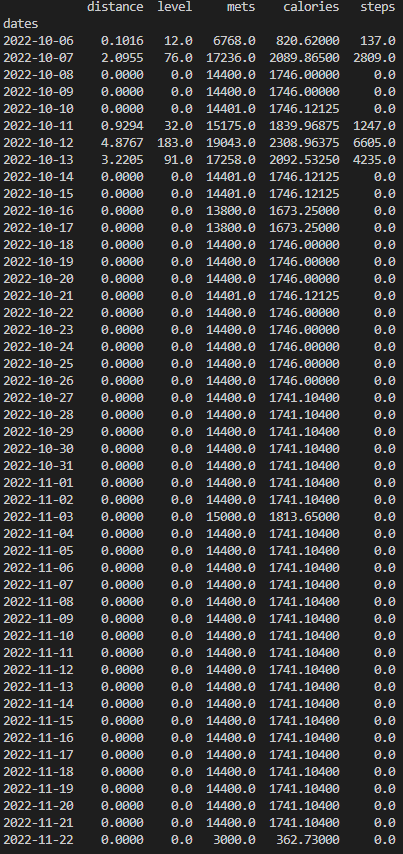
10월 6일부터 12월 22일까지 24시간동안 수집된 각 데이터들의 전체 합을 하루 단위로 나타낸 결과는 다음과 같다.
확실히 1분 단위의 데이터보다, 하루 단위로 데이터를 확인해보니 의미 있는 데이터만을 수집하기 위한 정보를 얻을 수 있다.
10월 6, 7, 11~13일을 제외하고는 distance의 값이 대부분 0이며, 다른 컬럼에 대한 데이터 값이 모두 일정하다는 것을 통해, 제대로 데이터가 수집되지 않았다는 것을 확인할 수 있었다.
위 데이터를 그래프로 시각화해보면 다음과 같다.
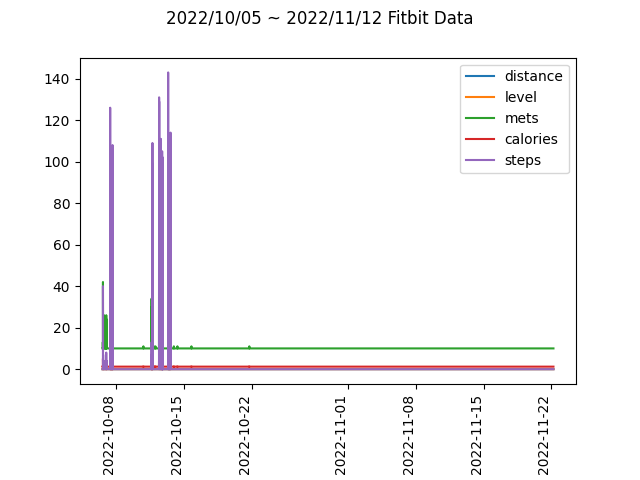
역시나 10월 초반의 몇몇 데이터를 제외하고, 10월 중순부터 11월 22일까지 데이터가 제대로 수집되지 않았음을 다시 한 번 확인할 수 있다.
시계열 데이터 준비
결국, 정확하게 fitbit 데이터를 수집한 날짜에 해당하는 데이터만을 선별하여 데이터를 분석해보는 것으로 결정하였다.
따라서 10월 11일부터 13일까지의 연속적인 구간에서의 데이터만을 따로 분석해보자.
다만, 올바르게 데이터가 수집되지 않은 날짜에 해당하는 데이터도 비교해보고자 10월 10일도 포함을 하였다.
아래와 같이 배열 arr에 10월 10일부터 10월 13일에 해당하는 데이터를 담았다.
get_group_by_hour() 함수는 각 날짜에 해당하는 데이터를를 60분 단위로 그룹핑하여, 각 컬럼의 모든 데이터들을 합한 새로운 DataFrame 객체를 반환하는 함수이다.
그룹으로 묶을 key 값이 datetime 객체인 경우, pandas의 Grouper 을 이용해 그룹핑 할 수 있다. Grouper을 이용해 freq 옵션 값을 60Min으로 지정하였고, base는 0으로 설정하여, 0분을 기준으로 한 시간 동안의 데이터의 누적 합이 저장되도록 지정하였다.
** pandas Grouper 참고 : https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Grouper.html
def get_group_by_hour(data):
return data.groupby(pd.Grouper(freq='60Min', base=0, label='right')).sum()
def result_by_time_series(data):
arr = [data.loc['2022-10-10'], data.loc['2022-10-11'], data.loc['2022-10-12'], data.loc['2022-10-13']]
result_arr = []
for a in arr:
result_arr.append(get_group_by_hour(a))
visualize_for_time_series(result_arr)
시계열 데이터의 시각화
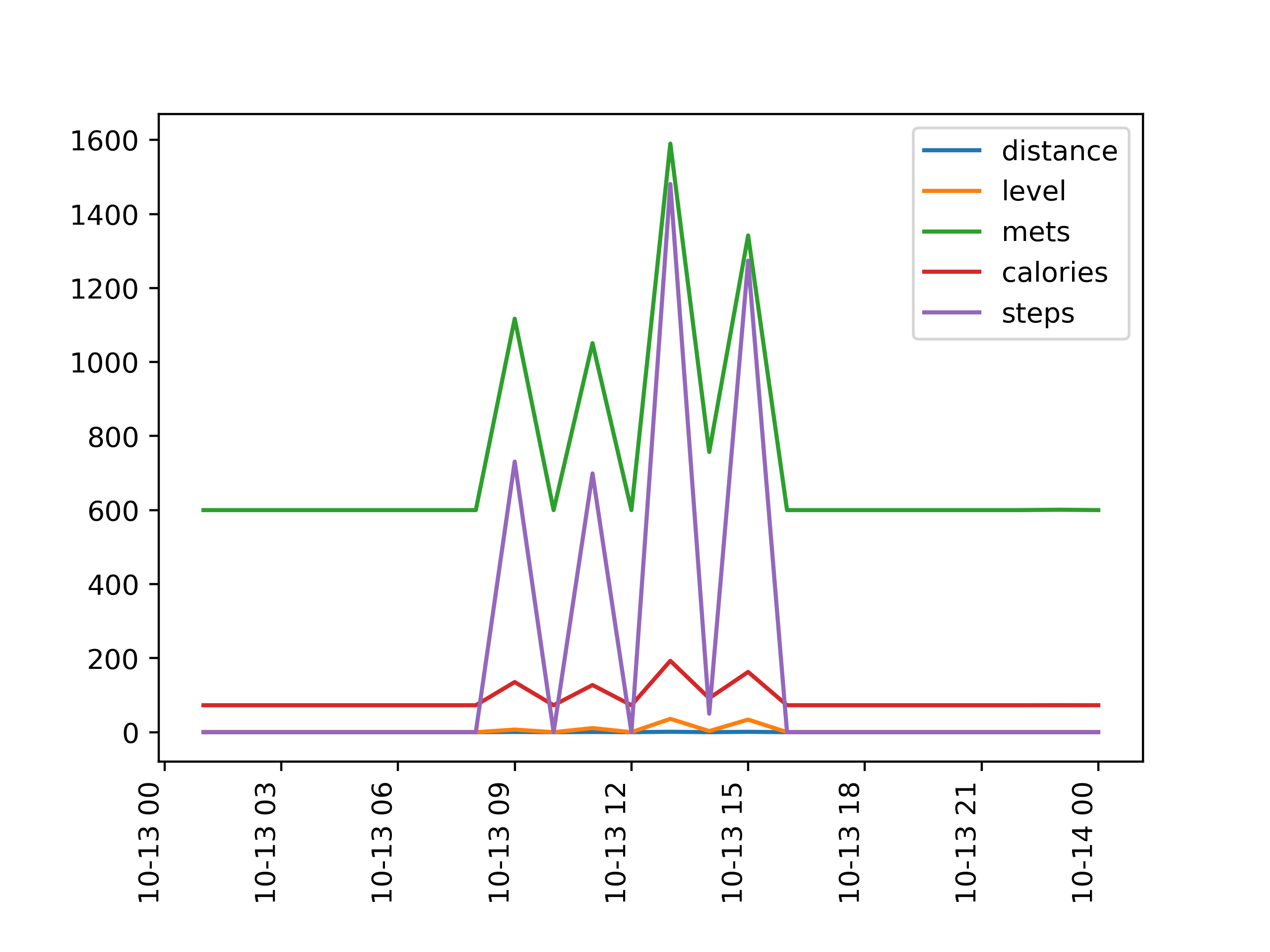
10월 10일부터 13일까지 총 4일간 각각 24시간동안 수집된 시계열 데이터를 그래프로 시각화해보자.
함수의 인자 data로는 총 4일간의 데이터, 즉 Dataframe 4개가 담겨 있는 배열이 들어간다.
matplotlib의 figure에 총 4개의 subplot을 추가하여 각 4일의 데이터를 그래프로 나타내보자.
각 ax 플롯에는, title, xalbel, ylabels, 그리고 xticklabels을 각각 지정하였다.
다만 각 날짜에 해당하는 데이터가 그래프로 더 자세하게 표현될 수 있도록, 하나씩 따로 윈도우로 figure이 생성되도록 추가하였다.
x_compat은 True로 rot은 90으로 지정하여 날짜와 시간이 x축의 값으로, 90도 반시계방향으로 회전하여 나타나도록 하여 각 날짜에 해당하는 figure을 추가적으로 표현 하였다.
def visualize_for_time_series(data):
fig = plt.figure()
for i in range(len(data)):
ax = fig.add_subplot(2,2,i+1)
day_data = data[i]
props={
'title':'2022-10-1' + str(i),
'xlabel':'Time',
'ylabel':'Numbers'
}
day_data.plot(x_compat=True, rot=90)
ax.plot(day_data)
ax.set_xticklabels(['00:00', '03:00', '06:00', '09:00', '12:00', '15:00', '18:00', '21:00', '24:00'], rotation=90, fontsize='small')
ax.set(**props)
plt.savefig('00 프로젝트/02 Health Data Project/data/image/fitbit_graph_2022-10-1{0}.png'.format(i), dpi=400)
plt.legend(loc='best')
plt.subplots_adjust(wspace=1, hspace=4)
plt.show()
figure에 나타난 4개 plot은 다음과 같다.
10월 11~13일의 경우 모두 각 칼럼의 데이터의 변화가 동시다발적으로 나타나는 것을 확인할 수 있다.
특히, 초록색 mets가 역시나 데이터의 범위가 매우 컸고, 이 데이터가 감소하고 증가함에 따라 빨간색으로 표시된 calories, 보라색 steps도 비슷한 양상으로 증가하고 감소하는 것을 알 수 있다.
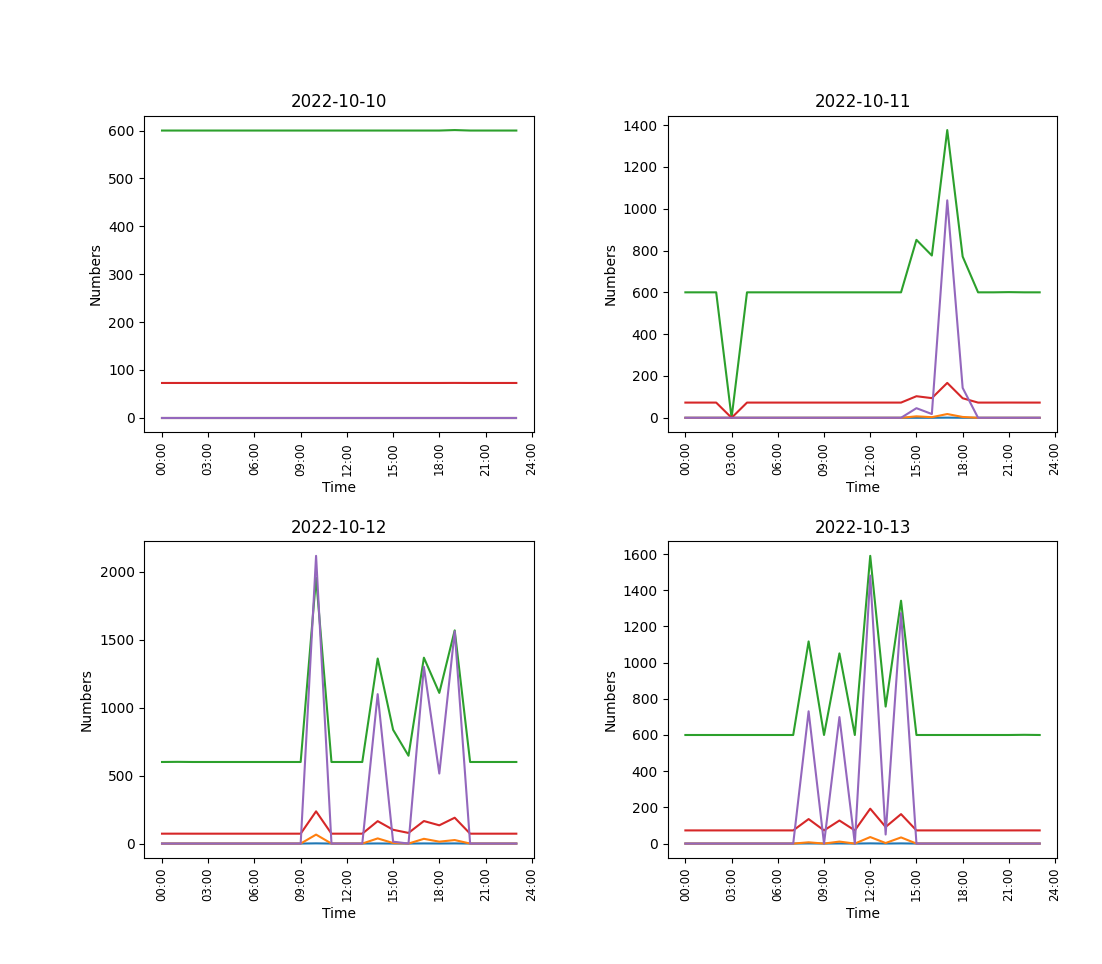
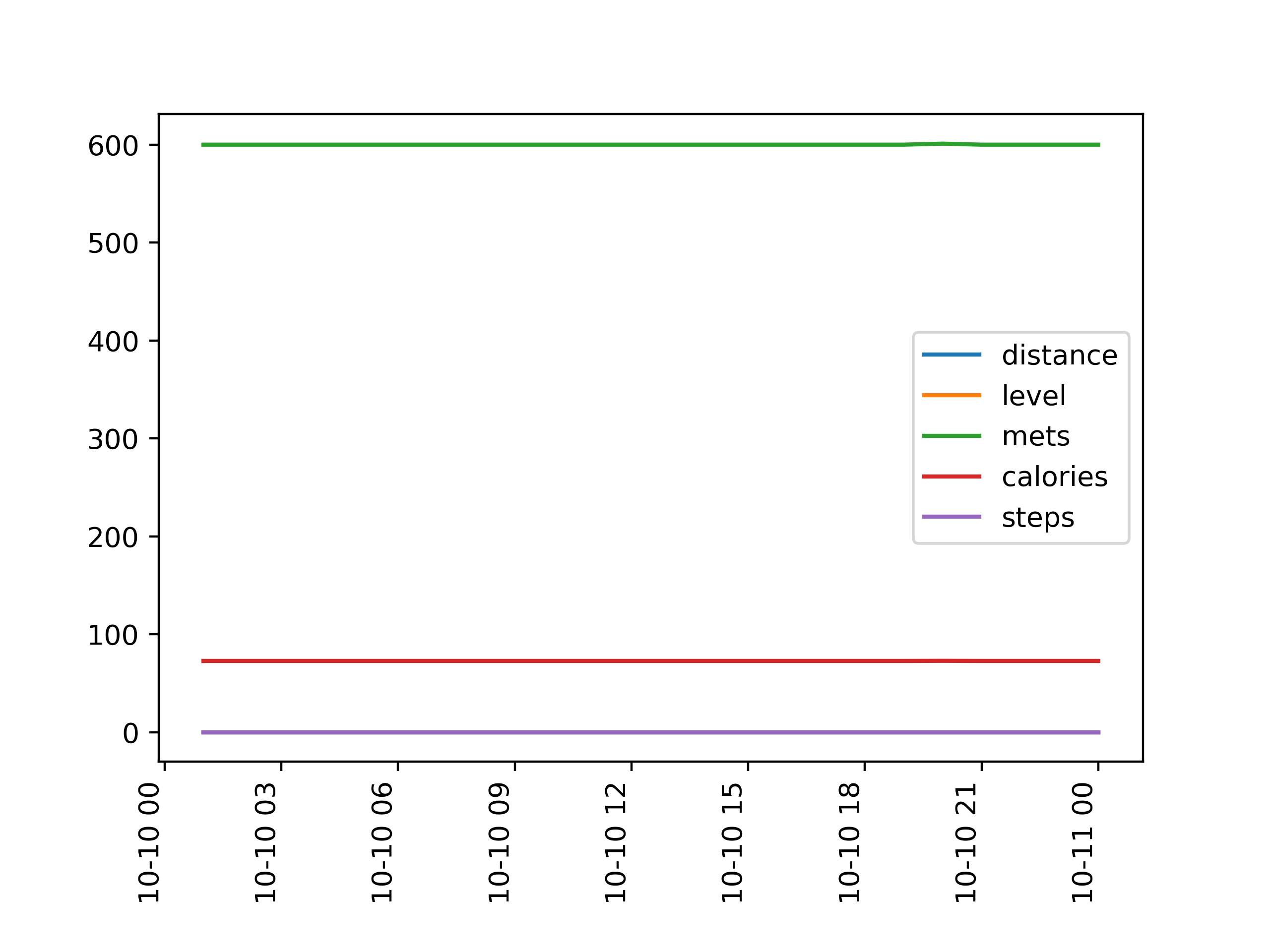
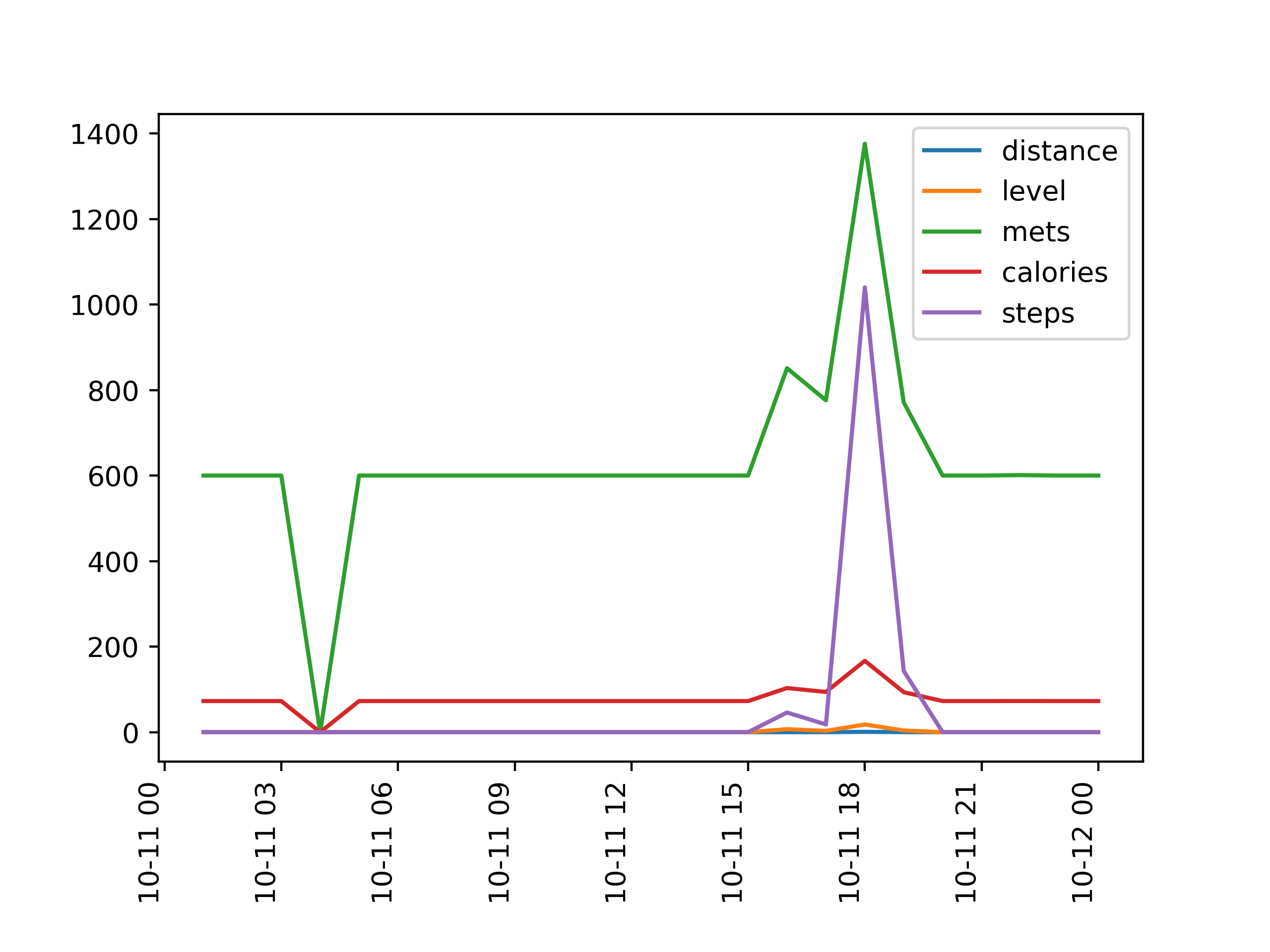
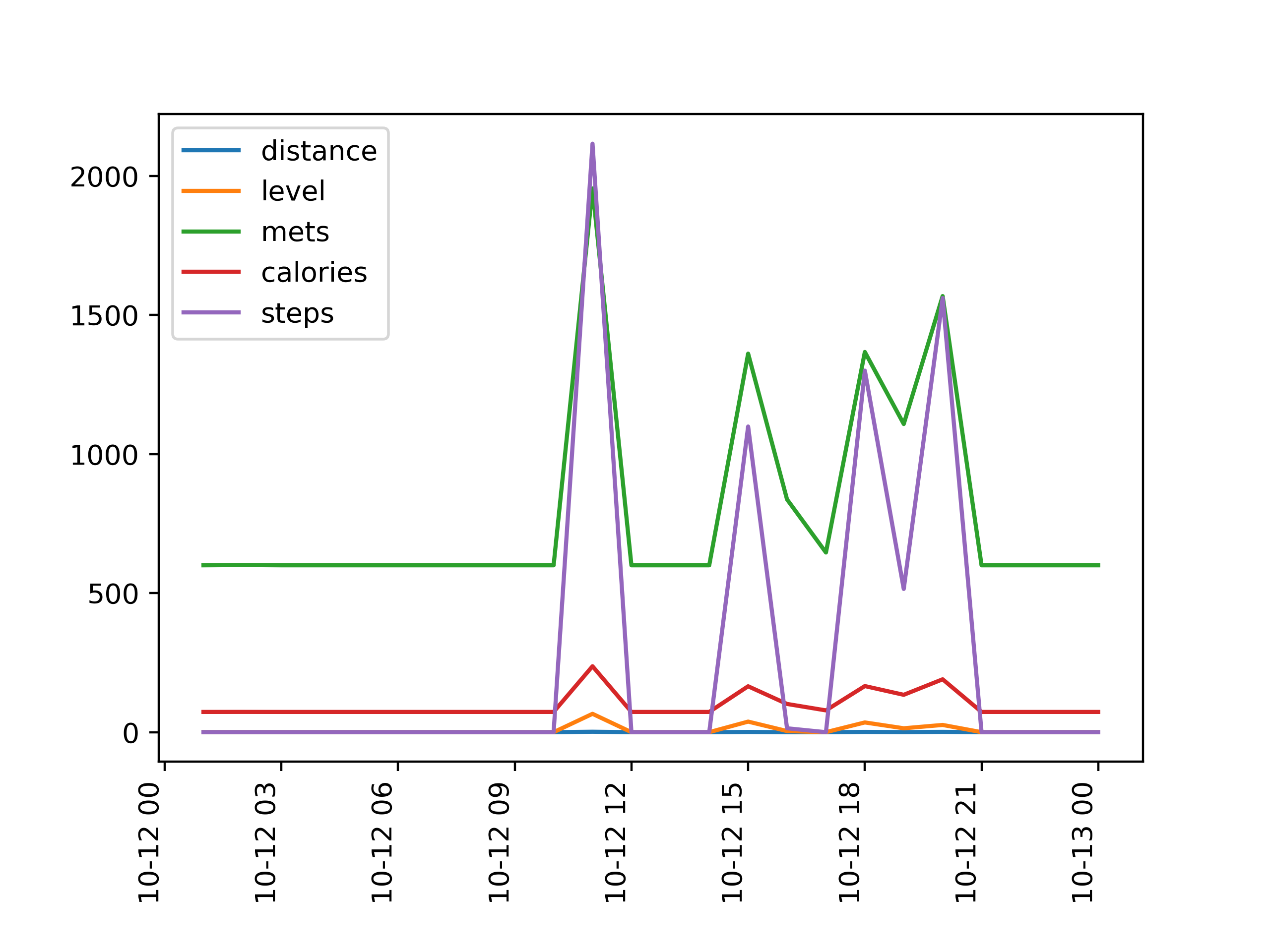
각 그래프를 다음과 같이 각각의 figure에 나타난 그래프로 조금 더 자세하게 확인해보자.
10월 10일은 역시나 데이터 수집의 이상으로 각 칼럼 데이터의 변화가 전혀 없음을 확인할 수 있다.
10월 11일의 경우, 오전 3~4시 경 mets와 calories 모두 급격히 0으로 감소했는데 이는 오류가 아닐까 하는 조심스러운 추축을 해본다. 다른 그래프에서도 볼 수 있다시피, calories와 mets 데이터는 값이 0으로 떨어지지 않기 때문이다. 11일, 측정 대상자는 6시~7시 사이 가장 높은 활동량이 측정되었고, calories,steps, mets에서 큰 변화가 있었다.
10월 12일의 경우, 사용자는 11시 경 가장 높은 활동량을 보였고, 차례대로 4시, 6시와 9시에도 높은 활동량이 측정되었다.
10월 13일의 경우 밤 시간대보다는 오전~오후 시간대에 전체적으로 높은 활동량이 나타났다.
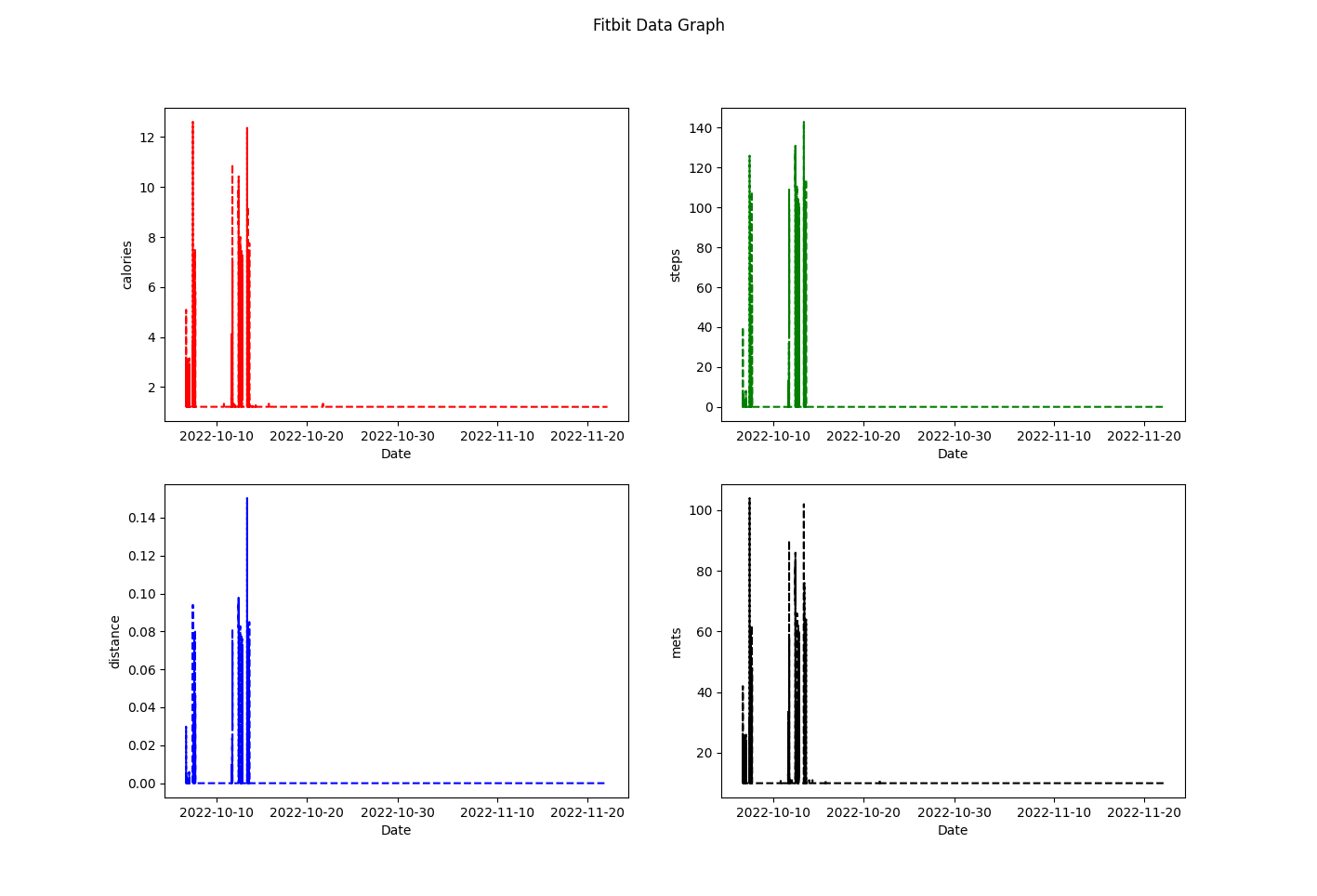
다음으로는, 4일간의 데이터가 아닌 전체 데이터를 각 칼럼별로, 그래프로 시각화해보자.
위의 분석을 통해 의미있다고 생각한 컬럼들인 calories, steps, distance, mets에 대한 데이터들을 전체 날짜 구간에 대하여 subplot에 나타내 보았다.
def visualize(data):
fig = plt.figure()
calories_ax = fig.add_subplot(2,2,1)
steps_ax = fig.add_subplot(2,2,2)
distance_ax = fig.add_subplot(2,2,3)
mets_ax = fig.add_subplot(2,2,4)
calories_ax.plot(data.index, data['calories'],'r--', label='calories')
steps_ax.plot(data.index, data['steps'], 'g--', label='steps')
distance_ax.plot(data.index, data['distance'], 'b--', label='distance')
mets_ax.plot(data.index, data['mets'], 'k--', label='distance')
calories_props={
'xlabel': 'Date',
'xticks':['2022-10-10', '2022-10-20', '2022-10-30', '2022-11-10', '2022-11-20'],
'ylabel': 'calories'
}
steps_props={
'xlabel': 'Date',
'xticks':['2022-10-10', '2022-10-20', '2022-10-30', '2022-11-10', '2022-11-20'],
'ylabel': 'steps'
}
distance_props={
'xlabel': 'Date',
'xticks':['2022-10-10', '2022-10-20', '2022-10-30', '2022-11-10', '2022-11-20'],
'ylabel': 'distance'
}
mets_props={
'xlabel': 'Date',
'xticks':['2022-10-10', '2022-10-20', '2022-10-30', '2022-11-10', '2022-11-20'],
'ylabel': 'mets'
}
calories_ax.set(**calories_props)
steps_ax.set(**steps_props)
distance_ax.set(**distance_props)
mets_ax.set(**mets_props)
plt.suptitle('Fitbit Data Graph')
plt.show()
결과는 다음과 같다.
역시나 10월 초중순에만 데이터의 증감이 나타나고, 나머지 구간에서는 데이터의 변화가 전혀 없다.
calories의 경우 0~12 사이의 값, steps의 경우 0~140의 값, distance의 경우 0~0.15의 값, mets의 경우 0~120 사이의 값의 범위가 나타남 또한 다시 한 번 확인할 수있다.
이번에는 전체 컬럼 간의 상관 관계를 나타내는 산점도로 시각화해보자.
seaborn 라이브러리의 pairplot을 이용하였다.
def pairplot(data):
sns.pairplot(data, hue_order=['calories', 'steps', 'mets', 'distance'])
plt.show()
pairplot을 통해 각 칼럼 간의 관계가 확연히 나타남을 확인할 수 있다.
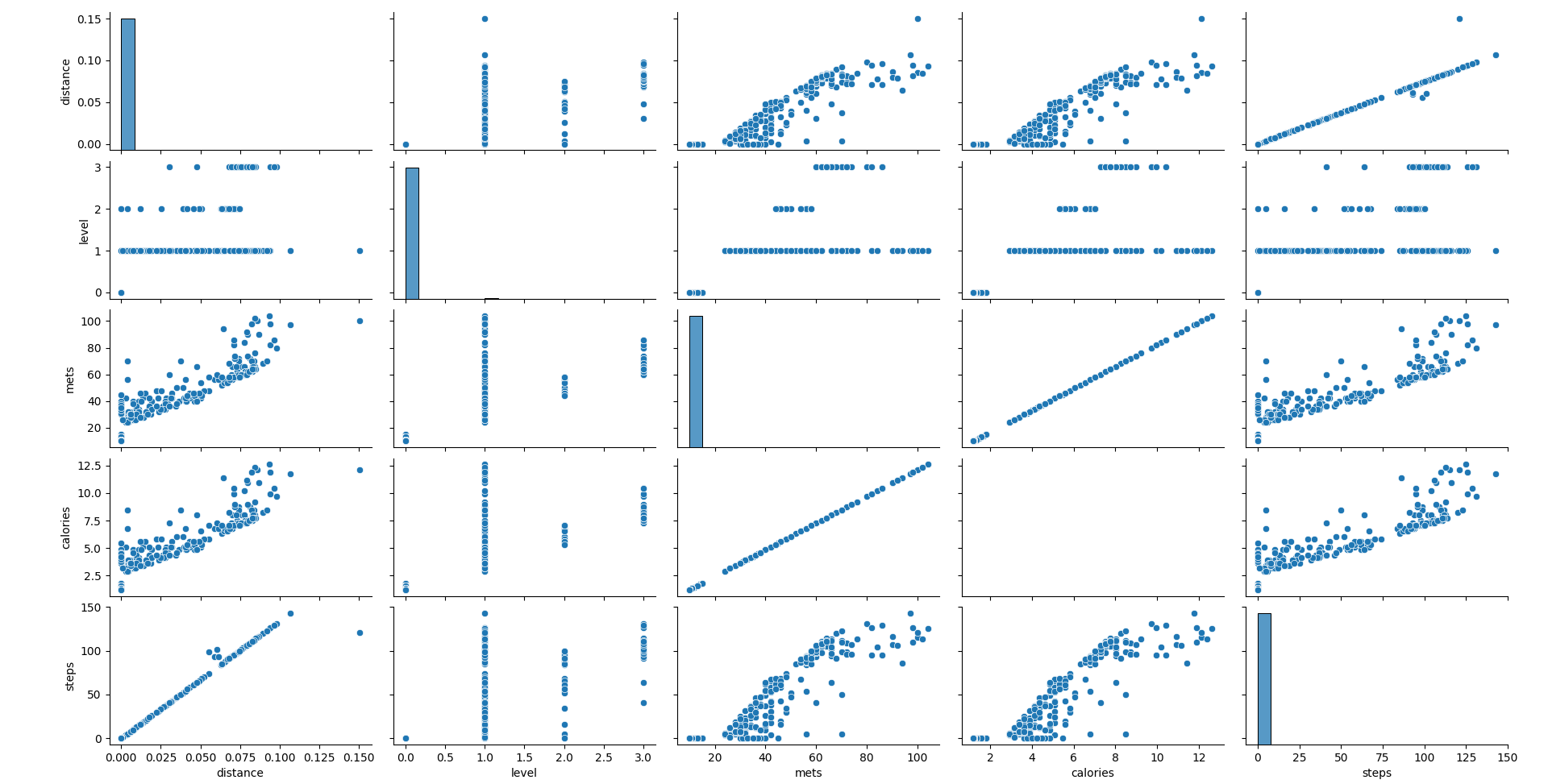
distance의 경우, 다른 칼럼들에 비해 값의 크기가 현저히 작았기 때문에 다른 칼럼과의 상관 관계를 분석하기 쉽지 않았지만, 산점도 scatterplot의 시각화를 통해 mets, calories, steps와 비슷한 증가세를 보임을 알 수 있었다.
산점도를 통해 데이터 값에 대한 정규화(normalization)를 따로 하지 않아도 되며, x, y 축이 각 칼럼의 값의 범위에 맞게 자동적으로 조절이 되어, 산점도가 칼럼 간의 상관관계를 파악하기에 매우 효율적인 도구임을 다시 한 번 깨달았다.
mets와 calories, steps 칼럼 데이터들은 역시나 서로 어느정도 선형 관계에 있음을 알 수 있다. (그러나 표본 상관 계수 r이 1을 띄는 정도는 아니다.)
'# Develop > Project' 카테고리의 다른 글
| [Java] Selenium, Web Driver을 이용한 웹 브라우저 제어 (0) | 2023.02.06 |
|---|---|
| [Python] 웹 스크래핑 하기 (내 블로그의 최신 글과 링크 가져오기) (0) | 2023.02.05 |
| MVC 패턴이란? (0) | 2022.11.14 |
| [Database Modeling] 원티드 채용 플랫폼의 채용 시스템 DB 모델링을 위한 사전 자료 조사 및 분석 (3) | 2022.10.21 |
| 카카오 소셜 로그인 과정 이해하기 (0) | 2022.09.27 |

