
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- C언어
- C++
- 카카오 코테
- @Autowired
- 알고리즘
- 카카오 알고리즘
- 코딩테스트
- 시스템호출
- 코테
- 구조체배열
- python
- 가상면접사례로배우는대규모시스템설계기초
- nestjs typeorm
- OpenCV
- 파이썬
- 카카오
- spring boot
- AWS
- 컴포넌트스캔
- 프로그래머스
- nestjs auth
- Nodejs
- nestJS
- thymeleaf
- git
- 해시
- 스프링
- TypeORM
- Spring
- @Component
Archives
- Today
- Total
공부 기록장 💻
[운영체제/OS] 02장 컴퓨터의 구조와 성능 향상 본문
컴퓨터의 구조와 성능 향상
- CPU와 메모리가 컴퓨터의 동작의 핵심이고, 운영체제를 이해하는데 가장 중요

1. 컴퓨터의 기본 구성
하드웨어의 구성
- 필수장치: 중앙처리장치(CPU), 메모리(메인메모리)
- 주변장치: 입출력장치, 저장장치(보조저장장치)

- CPU: 명령어를 해석하여 실행하는 연산장치
- 메모리
- 작업에 필요한 프로그램과 데이터를 저장하는 장소
- 바이트 단위로 분할되어 있으며 분할 공간마다 주소(address)로 구분
- 저장장치
- 메모리(RAM)보다는 느리지만 저렴하고 용량이 큼(SSD, SD카드)
- 전원의 On/Off와 상관없이 데이터를 영구적으로 저장
- 메인 보드
- CPU와 메모리 등 다양한 부품을 연결하는 커다란 판
- 전력이 공급되면 버스로 연결된 부품이 작동
- 그래픽 카드, 사운드카드, 랜 카드 등이 기본적으로 장착되어 있기도 하고, 성능 향상을 위해 따로 장착하기도 함
폰노이만 구조
- CPU, 메모리, 입출력장치, 저장장치가 버스로 연결되어 있는 구조
- HW는 그대로 둔 채, 작업을 위한 프로그램만 교체하여 메모리(전자식 기억장치)에 올리는 형식 → CPU는 메모리에 내장된 프로그램을 불러와 수행 (내장형 메모리 구조)
- 모든 프로그램은 메모리에 올라와야 실행할 수 있다.
- 현대 컴퓨터 시스템의 구조 → HW가 아닌 프로그램 코드 변경으로 사용이 용이


요리사 모형
- 요리 방법을 결정하는 것은 CPU가 작업을 진행하는 것(프로세스 관리)에, 도마 위의 재료를 정리하는 것은 여러 프로그램이 사용하는 메모리를 관리하는 것(메모리 관리)에, 보관 창고의 재료를 정리하는 것은 저장장치 내 데이터를 관리하는 것(저장장치 관리)에 비유
- 도마의 크기가 곧 메모리의 크기가 되고, 작업 속도가 결정된다.
- 도마가 크면 재료를 많이 가져다 놓고 요리할 수 있지만, 도마가 작으면 재료 하나를 다듬어 보관 창고에 가져다 놓은 뒤 다른 재료를 가져와야 하므로 작업 속도가 떨어지게 됨
하드웨어 사양 관련 용어
- 클록(Clock)
- CPU의 속도와 관련된 단위
- 일정 간격으로 틱(tick)을 만들면 거기에 맞추어 CPU 안의 모든 구성 부품이 작업됨
- 메인보드의 클록이 틱을 보낼 때마다 데이터를 보내거나 받음
- 헤르츠(Hz)
- 클록 틱이 발생하는 속도를 나타내는 단위
- 1초에 클록틱이 한번 발생 → 1Hz
- 3.4GHz → 1초에 클록틱이 3.4 X 10^9 번 발생하여 1초에 약 34억 번의 연산을 함
- 시스템 버스 : 메모리와 주변 장치를 연결하는 버스
- CPU 내부 버스 : CPU 내부의 장치를 연결하는 버스
- CPU의 클록과 같아서 시스템 버스보다 훨씬 빠름
- CPU와 메모리 속도 (두 버스의 속도 차이로 인해 작업이 지연되는 문제 발생)
- CPU → CPU 내부 버스의 속도로 작동
- 메모리 → 시스템 버스의 속도로 작동
2. CPU와 메모리
CPU 구성과 동작
- 산술 논리 연산장치 (ALU)
- 데이터의 덧셈, 뺄셈, 곱셈, 나눗셈 등의 산술 연산과 AND, OR 같은 논리 연산 수행
- 제어 장치
- 레지스터에 있는 데이터를 가져다가 명령어를 해석과 실행을 지시
- CPU에 작업을 지시
- 레지스터
- CPU 내에 데이터를 임시로 보관
CPU 명령어 처리 과정
- CPU가 연산을 수행하기 위해서는, 필요한 데이터를 메모리에서 CPU로 가져와 임시로 보관해야 하는데, 사용되는 장소가 바로 레지스터이다.
- 모든 데이터가 준비되면, 산술논리 연산 장치에서 연산을 수행하고, 레지스터에 저장하였다가, 최종적으로 메모리에 옮긴다.
- 이 모든 명령어는 제어 장치에서 CPU에 작업을 지시한다.

레지스터의 종류와 특징
사용자 가시 레지스터
- 데이터 레지스터(DR) : CPU가 명령어를 처리하는데 필요한 일반 데이터를 임시로 저장
- 주소 레지스터(AR) : 데이터, 명령어가 저장된 메모리의 주소를 저장
사용자 불가시 레지스터(특수 레지스터)
- 프로그램 카운터(PC): 다음에 실행할 명령어의 주소를 기억하고 있다가 제어 장치에 알려줌(명령어 포인터)
- 명령어 레지스터(IR) : 현재 실행 중인 명령어 저장
- 제어 장치는 명령어 레지스터에 있는 명령을 해석한 후 외부 장치에 적절한 제어 신호를 보냄
- 메모리 주소 레지스터(MAR) : 메모리 관리자가 접근해야 할 메모리의 주소를 저장
- 메모리 버퍼 레지스터(MBR) : 메모리 관리자가 메모리에서 가져온 데이터를 임시로 저장
- 프로그램 상태 레지스터(PSR) : 산술 논리 연산 장치와 연결되어 연산 결과(양수, 음수 등)을 저장


버스의 종류
- CPU 내부 버스
- 시스템 버스
- 제어 버스
- 다음에 어떤 작업을 할지 지시하는 제어 신호 이동
- 읽기 신호, 쓰기 신호 등
- ex) LOAD, ADD, MOVE 등
- 주소 버스
- 데이터가 있는 메모리의 위치 정보(주소) 이동
- 주변장치(하드디스크)의 위치
- CPU에서 메모리 주소 레지스터로 전달
- 데이터 버스
- 제어 버스가 작업의 신호를, 주소 버스가 위치 정보를 전달하면, 데이터 버스에 데이터가 실려 이동
- 제어 버스

버스의 대역폭(bandwith)
- 한번에 전달할 수 있는 데이터의 최대 크기
- CPU가 한 번에 처리할 수 있는 데이터의 크기(word)와 같음
- 32bit CPU → 한번에 최대 32bit를 처리 가능 (레지스터의 크기도 32bit, 버스의 대역폭도 32bit)
- 버스의 대역폭 = 레지스터의 크기 = 메모리에 한 번에 저장할 수 있는 데이터의 크기 = Word size **
메모리
- 모든 프로그램은 메모리에 올라와야 실행될 수 있다.
- CPU와 협업하여 작업이 이루어진다.
- 메모리 주소는 바이트 단위로, 메모리에서 데이터를 읽고 쓸 때는 워드 단위로 움직임
메모리의 보호 필요성
- 현대 사용하고 있는 운영체제의 시분할 기법 → 여러 프로그램을 동시에 실행하므로 사용자 영역이 여러 개의 작업 공간으로 나뉘어져 있어 한 작업이 다른 작업의 영역을 침범하여 프로그램을 파괴하거나 데이터를 삭제하지 않기 위해 메모리 보호가 필요
- 운영체제도 CPU를 사용하는 소프트웨어 작업 중 하나이기 때문에 다른 작업이 운영체제 영역을 침범하려는 악성 소프트웨어에 대한 보호가 필요함
메모리 보호 방법
- 현재 진행 중인 작업의 메모리 시작 주소를 경계 레지스터(base register)에 저장 후 작업
- 작업이 차지하고 있는 메모리 크기(마지막 주소까지의 차이)를 한계 레지스터(limit register)에 저장
- 작업이 데이터를 읽거나 쓸 때 CPU는 해당 작업이 위 두 레지스터의 주소 범위를 벗어나는지 HW적으로 점검 (주소 영역 체크)
- 두 레지스터의 값을 벗어나는 경우 메모리 오류와 관련한 인터럽트가 발생 → 모든 작업이 중단되고 CPU는 OS를 깨워 인터럽트를 처리하도록 시킴 (해당 프로그램 강제 종료)

메모리 부팅 **
- 컴퓨터를 켰을 때 운영체제를 메모리에 올리는 과정
- 컴퓨터 ON → OS를 가장 먼저 메모리에 올라가고, 이후에 다른 서비스들을 메모리에 올리게 됨
1) 전원 ON ⇒ ROM의 BIOS(일종의 펌웨어) 동작하며 하드웨어를 점검
2) 이상이 없는 경우, 하드디스크의 마스터 부트 레코드에 저장된 작은 프로그램을 가져와 실행
- OS의 이미지를 확인하여 마스터 부트 레코드(MBR)의 정보를 가져옴
- OS의 시작 위치, 하드디스크의 첫번째 섹터인 메모리의 첫번째 실행 코드를 메모리상에 올림
3) 부트스트랩 코드가 실행되며 OS의 첫번째 명령어가 실행됨

3. 컴퓨터 성능 향상 기술
- 문제점: CPU와 메모리, 주변 장치의 작업 속도가 다르다는 것
→ 장치 간 속도 차이를 개선하고 시스템의 작업 속도를 올리기 위해 개발된 기술 중 OS와 관련된 기술은 무엇이 있을까?
버퍼
- 속도에 차이가 있는 두 장치 사이에서 그 차이를 완화하는 역할을 하는 장치
- 일정량의 데이터를 모아 옮김으로써 속도의 차이를 완화
- ex) 동영상 스트리밍의 경우 - 3MB/s(24Mbps) 이상으로 재생되어야 고화질로 시청할 수 는 경우, 네트워크 속도가 이를 최소한 보장해야 하는 상황에서 버퍼를 두게 되면, 동영상 데이터의 일정 부분을 버퍼에 넣으면 재생 시작이 조금 늦어질 수 있겠지만(버퍼링), 그 이후에는 정상적인 재생이 가능
스풀(Spool)
- CPU와 입출력장치가 독립적으로 동작하도록 고안된 소프트웨어 버퍼
- 인쇄할 내용을 순차적으로 출력하는 SW로, 출력 명령을 내린 프로그램과 독립적으로 동작
- ex) 프린터에 사용되는 스풀러 - 인쇄할 내용을 순차적으로 출력하는 SW(인쇄물이 완료될 때까지 다른 인쇄물이 끼어들 수 없으므로 프로그램 간에 배타적)

캐시(Cache)
캐시의 개념
- 메모리와 CPU 간의 속도 차이를 완화하기 위해 메모리의 데이터 일부를 미리 가져와 저장해두는 장치 (CPU에 붙어있는 모듈)
- 필요한 데이터를 모아 한꺼번에 전달하는 버퍼의 일종 → CPU가 앞으로 사용할 것으로 예상되는 데이터를 미리 가져다 놓음(prefetch)
- CPU 내부에 있으며 CPU 내부 버스의 속도로 작동하며, CPU와 메모리 사이에서 두 장치의 속도 차이를 완화한다.
- CPU가 메모리에 접근해야 할 때 캐시를 먼저 방문하여 원하는 데이터가 있는지 찾아봄
- 캐시 히트(cache hit): 캐시에서 원하는 데이터를 발견한 경우 바로 사용
- 캐시 미스(cache miss): 캐시가 없으면 메모리 가서 다시 탐색
- 캐시 적중률(cache hit ratio): 캐시 히트가 되는 비율(일반적으로 90%)
캐시 적중률을 높이는 방법
- 캐시의 크기를 늘림 (더 많은 데이터를 미리 가져올 수 있어 캐시 적중률 상승)
- 앞으로 많이 사용될 데이터를 가져오는 것
- 현재 위치에 가까운 데이터가 멀리 있는 데이터보다 사용될 확률이 더 높다는 지역성 이론에 기반
- ex) 현재 10번 행이 실행되고 있는 경우, 11~20번 행을 미리 가져옴
캐시의 구조

즉시 쓰기와 지연 쓰기
캐시에 있는 데이터가 변경되는 경우, 메모리에 어떻게 반영할 것인가?
- 즉시 쓰기(write through): 데이터 동기화 - 캐시의 데이터가 변경되면 이를 즉시 메모리에 반영
- 빈번한 메모리 데이터 전송으로 성능이 느려짐
- 메모리의 최신 값이 항상 유지됨
- 지연 쓰기(write back): 변경된 데이터 내용을 모아 주기적으로 반영
- 메모리와의 데이터 전송 횟수가 줄어 시스템의 성능 향상
- 메모리와 캐시된 데이터 사이의 불일치 발생
L1 캐시와 L2 캐시
- 프로그램 명령어2) 데이터 부분 - 작업의 대상
- 1) 명령어 부분 - 어떤 작업을 할 것인지?
- L1캐시(특수캐시)
- 명령어 캐시는 명령어 레지스터와, 데이터 캐시는 데이터 레지스터와 연결되어 있으며, CPU 레지스터에 직접 연결되어 있음
- L2캐시(일반캐시)
- 메모리와 연결되어 있음
- 시스템 성능 향상을 위해선 L2 캐시를 사용하는 것이 좋다. (자주 쓰는 데이터를 L2 캐시에 저장할 수 있으므로, 시스템 버스를 사용하는 것을 줄일 수 있다.)

저장장치의 계층 구조
- 속도(가격)와 용량이 반비례함
- 속도가 빠르고 값이 비싼 저장장치(레지스터, 캐시)를 CPU와 가까운 쪽에 두고, 값이 싸고 용량이 큰 저장장치(메모리, 저장장치)를 반대쪽에 배치

인터럽트
- IO처리를 위해 쓰는 방식
- 입출력 관리자 (IO Manager)에게 CPU는 명령어를 던져, 입출력 관리자가 다음 처리를 함
폴링 방식(polling)
- CPU가 직접 입출력장치에서 데이터를 가져오거나 내보내는 초기 컴퓨터 시스템의 방식
- CPU가 입출력장치의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 데이터를 처리
- 명령어 해석과 실행(연산 수행)이라는 본래 역할 외에 모든 입출력까지 관여하기 때문에 전체적인 작업 효율이 떨어짐
인터럽트
- CPU가 입출력 관리자에게 입출력 명령(read, write 등)와 데이터 위치를 보내면, 입출력 관리자가 데이터를 메모리에 가져다 놓거나, 메모리에 있는 데이터를 저장장치로 옮겨, 입출력 관리자는 완료 신호를 CPU에 보냄
- 인터럽트: 입출력 관리자가 CPU에게 보내는 완료 신호(메세지)
- 입출력 관리자에게 작업 지시를 내리고, 다른 일을 하다가 완료 신호를 받으면 하던 일을 중단하고 옮겨진 데이터를 처리함
- IRQ(인터럽트 번호, Interrupt ReQuest): 주변 장치 중 어떤 것의 작업이 끝났는지를 CPU에 알려주기 위해 사용하는 번호
- ex) 윈도우의 경우 키보드의 IRQ는 1번, 마우스의 IRQ는 2번
- 인터럽트 벡터: 여러 개의 입출력 작업을 하나의 배열로 만든 것
- 해당 인덱스에 해당하는 장치(프린트)의 작업이 완료됨을 표시
인터럽트 방식의 동작 과정

- ex) 사용자가 컴퓨터의 전원 버튼을 눌러 강제로 종료하는 경우 → CPU는 하던 일을 모두 멈추고 처리 중인 데이터를 안전하게 보관한 뒤 시스템을 종료
- ex) 메모리에서 실행 중인 어떤 작업이 자신에게 주어진 메모리 영역을 넘어서 작업을 하는 경우
- ex) 0으로 숫자를 나누는 경우
직접 메모리 접근(Direct Memory Access, DMA)
- 입출력 관리자가 CPU의 허락 없이 직접 메모리에 접근하여 작업을 수행할 수 있는 권한
- 시스템 컨트롤를 다 하면 위험하므로, 입출력 관리자의 작업 영역을 별도로 지정하여 사용할 수 있도록 해야 함

메모리 매핑 입출력(Memory Mapped IO)
- 직접 메모리 접근을 통해 들어오는 데이터와 CPU 가 사용하는 메모리 공간을 분리하는 기법
- 메모리의 일정 공간을 입출력에 할당하는 기법

사이클 훔치기(Cycle Stealing)
- CPU와 직접 메모리 접근이 동시에 접근하는 경우, CPU가 메모리 사용 권한을 양보 (CPU의 작ㄱ업 속도보다 입출력장치의 속도가 느리기 때문에 양보
- CPU보다 DMA(직접 메모리 접근)이 먼저 메모리에 사용할 수 있도록 함
Device / IO Manager ↔(interrupt) CPU(ALU, controller, Register, Cache) / Memory
4. 병렬 처리
- CPU의 성능을 향상하는 좋은 방법 → CPU의 클록을 높이거나 캐시의 크기 늘리는 것 (발열 문제 발생)
- → 다수 코어를 두거나, 동시에 실행 가능한 명령의 개수를 늘리는 방법 사용
병렬 처리의 개념
- 병렬 처리(parallel processing): 동시에 여러 개의 명령을 처리하는 방식
- 파이프라인기법: 하나의 코어에 여러 개의 스레드를 이용하는 방식(멀티스레드)

- 슈퍼스칼라 기법: 2개의 코어 CPU를 이용하여 2개의 작업을 동시에 처리하는 방식
- 여러 명의 요리사를 두는 방식
병렬 처리 시 고려 사항
- 상호 의존성이 없어야 함
- 각 명령어가 서로 독립적이고 앞의 결과가 뒤의 명령에 영향을 미치지 않아야 함
- 각 단계의 시간을 일정하게 맞춰야 병렬 처리가 원만하게 이루어짐
- 각 단계의 처리 시간이 들쑥날쑥하면 앞의 작업이 먼저 끝나더라도 가장 긴 시간이 걸리는 단계에서 병목 현상 발생
- 대기 시간이 발생하므로 전체 작업 시간이 늘어야 성능이 저하됨
- 전체 작업 시간을 몇 단계로 나눌지 잘 따져보아야 함
- 병렬 처리의 깊이(depth of parallel processing) N: 동시에 처리할 수 있는 작업의 개수

병렬 처리 기법
CPU에서 명령어가 실행되는 과정
- 스레드: CPU 내에서 제어장치가 명령어를 가져와 해석한 후 실행하고 결과를 저장하는 과정 전체
- 명령어 패치(IF, Instruction Fetch) : 다음에 실행할 명령어를 명령어 레지스터에 저장
- 명령어 해석(ID, Instruction D)
- 실행(EX, Execution) : 해석한 결과를 토대로 명령어를 실행
- 쓰기(WB, Write back) : 실행된 결과를 메모리에 저장
1. 파이프라인 기법

- 명령을 겹쳐서 실행하는 방법
- 하나의 코어에 여러 개의 스레드를 사용
- 명렁어를 여러 개의 단계로 분할한 후, 각 단계를 동시에 처리하는 HW를 독립적으로 구성
파이프라인 위험
- 데이터 위험: 데이터 의존성으로 인해, 명령어 단계를 지연하여 해결

- 제어 위험: if문 또는 goto 문으로 인해 프로그램 카운터 값을 갑자기 변화 시켜, 다음 문장이 아닌 다른 문장으로 이동하는 경우 현재 동시에 처리되고 있는 명령어들이 쓸모 없어진다. → 분기 예측, 분기 지연 방법으로 해결

- 구조 위험: 서로 다른 명령어가 같은 자원에 접근하려 할 때 충돌 발생

2. 슈퍼스칼라 기법
- 코어를 여러 개 구성하여 복수의 명령어가 동시에 실행되도록 하는 방식
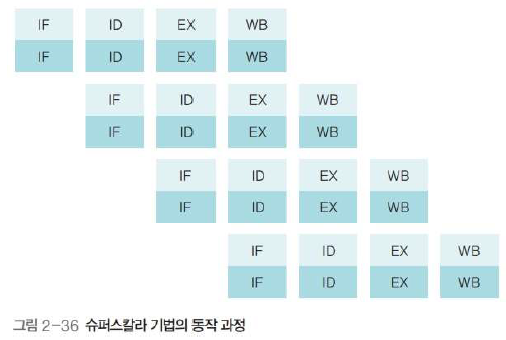
3. 슈퍼파이프라인 기법
- 파이프라인의 각 단계를 세분화하여 한 클록 내에 여러 명령어를 처리

4. 슈퍼파이프라인 슈퍼스칼라 기법
- 슈퍼파이프라인 기법을 여러 개의 코어에서 동시에 수행

5. VLIW 기법(Very Long Instruction Word)
- CPU가 병렬 처리를 지원하지 않는 경우 소프트웨어적으로 병렬 처리를 수행 (동시에 수행 가능한 명령어들을 컴파일러가 추출하고 하나의 명령어로 압축하여 실행)
- 컴파일 시 병렬 처리 수행
728x90
반응형
'# CS Study > Opearing System' 카테고리의 다른 글
| [운영체제/OS] 쉽게 배우는 운영체제 03장 문제 풀이 (프로세스) (0) | 2022.08.21 |
|---|---|
| [운영체제/OS] 03장 프로세스 (0) | 2022.08.21 |
| [운영체제/OS] 쉽게 배우는 운영체제 2장 문제풀이 (컴퓨터의 구조와 성능 향상) (0) | 2022.08.20 |
| [운영체제/OS] 쉽게 배우는 운영체제 1장 문제 풀이 (운영체제의 개요) (0) | 2022.08.20 |
| [운영체제/OS] 01장 운영체제의 개요 (1) | 2022.08.20 |
'# CS Study/Opearing System' Related Articles
more


Comments